
Elasticsearch mimarisinin merkezinde node lar ve cluster bulunmaktadır. Node verileri depolayan ve cluster ın parçası olan bir sunucudur. Bir cluster node lardan oluşur, yani sunuculardan. Her node, cluster a eklenen veriler olan, cluster verilerinin bir bölümünü oluşturur.
Her node, cluster ın indeksleme ve arama yeteneklerine katılır, yani bir node depoladığı verileri arayarak belirli bir arama sorgusuna katılır.
Bir node verilerin bir bölümünü içerir ve node verileri aramayı ve yeni verileri indekslemeyi veya mevcut verileri değiştirmeyi destekler.
Cluster içerisinde ki her node, cluster a istek göndermek isteyen clientlerin HTTP isteklerini işler. Bu cluster ın sunduğu HTTP REST API kullanılarak yapılır. Belirli bir node daha sonra client in bu isteğini alır ve işin geri kalanını koordine eder. Ayrıca cluster içerisindeki bir node diğer tüm node ları bilirken istekleri bir taşıma katmanı kullanarak belirli bir node a iletebilir ve HTTP katmanı yalnızca harici clientler ile iletişim kurabilmek için kullanılır. Tüm node lar varsayılan olarak clientlerden gelen HTTP isteklerini kabul ederler.
Her node varsayılan olarak master node olarak atanabilirler. Master node, node ların eklenmesi veya kaldırılması, indexlerin oluşturulması veya kaldırılması gibi cluster daki değişiklikleri koordine etmekten sorumludur. Master node, cluster içerisinde cluster ın durumunu güncelleyebilen tek node dur.
Hem node lar hemde clusterlar benzersiz bir adla adlandırılmalıdırlar.
Cluster içerisinde tutulan her veri öğesine, indexe eklenen temel bir bilgi birimi olan document adı verilir. Document ler json nesneleridir ve ilişkisel vertabanında satırlara karşılık gelirler. Document ler index adı verilen bir şey içinde tutulurlar. Bir indeks, biraz benzer özelliklere sahip, mantıksal olarak ilişkili olan bir document koleksiyonudur. İdeasoft yapımızda index içerisindeki mantıksal ilişki document lerin yani ürünlerin aynı müşteriye yani web sitesine ait olmasıdır.
Document lere, elasticsearch tarafından otomatik olarak veya bizim tarafımızdan atanan kimlikler vardır. Bir document, index ve kimliğiyle benzersiz unique bir şekilde tanımlanır.
Elimizde 1 terabaytlık veri içeren bir index olduğunu düşünelim. Cluster ımızda da 512 gigabaytlık iki node olsun. Tüm index tek bir node a sığmaz ve parçalamamız gerekir. Tüm index iki node arasında bölüyoruz ve böylece tüm indexi etkin bir şekilde kullanmış oluyoruz.
Bir index in boyutu tek bir node un donanımsal sınırlarını zorladığı zaman sharding yapmak gerekir. Bir shard, index verilerinin bir alt kümesini içeririr ve kendi içinde tamamen işlevsel, bağımsızdır.
Bir index sharding yapıldığı zaman, o indexteki belirli bir document yalnızca shard lardan birine depolanır.

Sharding ile ilgili önemli olan bir özellikte cluster içerisinde herhangi bir node da barındırılabilmeleridir.
Sharding in 2 önemli özelliği vardır:
Shard sayısı isteğe bağlı olarak index oluştururken belirlenebilir ama belirtilmezse default olarak 5 kullanılacaktır. Bu değer diğer index lerde göz önünde bulundurularak, index te bulunan veri miktarına ve node ların donanımsal özelliklerine bağlıdır.
İndex oluşturulduktan sonra, index için shard sayısını arttırmak mümkün değildir. Shard arttırmak istenirse bir index için yeni bir index oluşturulur istenilen shard sayısı ile ve datalar bu yeni index e taşınır.
Özetle bir index in veri hacmini bölmeye sharding denir. Bu şekilde bir cluster içerisinde verileri birden çok node a dağıtarak kullanabiliriz.
Elasticsearch yeni bir document i hangi shardda tutacağını nereye göre belirler ona değineceğiz.
Elasticsearch te yönlendirme otomatik olarak yapılır, varsayılan olarak bir yönlendirme formülü kullanır.

Varsayılan olarak yönlendirme değeri belirli bir documentin kimliğine eşit olacaktır. Bu değer daha sonra sharding için kullanılabilecek bir sayı üreten bir hashing işleminden geçer. Oluşturulan sayının indexteki primary shard sayısına bölünmesinin geri kalanı (mod) sharda numarasını verecektir. Elasticsearch belirli document lerin konumunu bu şekilde belirler. Yani bir document ararken (eğer ki özel document id si ile aramıyorsanız) farklı işlenerek tüm node lara query yayınlanır.
Bir index oluşturulduktan sonra index in shard sayısının değiştirelemeyeceğinden yukarıda bahsetmiştik. Yönlendirme formülünü göz önünde bulundururarak, shard sayısını değiştirirsek, yönlendirme formülünü çalıştırmanın sonucunda document ler değişir. 5 shard var iken shard A da bir document olduğunu düşünelim. Shard sayısını 7 olarak değiştirdiğimizde, documenti kimliğine göre aramaya çalışarak yönlendirme formülünün sonucu farklı olabilir. Document aslında shard A depolansa bile formül, shard B ye yada başka bir sharda yönlendirebilir. Bu nedenle bir index oluşturduktan sonra shard sayısı değiştirilemez ve bu nedenle yeni bir index oluşturmak ve documentleri oraya taşımak gerekir. Varsayılan yönlendirme formülü kullanılarak da yönlendirilen document leri içeren bir indexe özel yönlendirme eklenirse de aynı problem ortaya çıkabilir.
Bundan dolayı tavsiye edilen varsayılan yönlendirme formülü kullanarak document leri bir index in primary shardlarına eşit olarak dağıtmasıdır.
Elasticsearch local olarak replication destekler. Yani shardlar kopyalanır(replication).
Bir shard çoğaltığında buna replica shard yada sadece replica denir. Çoğaltılan shardlara primary shard denir. Primary shard ve replica sharda çoğaltma grubu (replication group) denir.
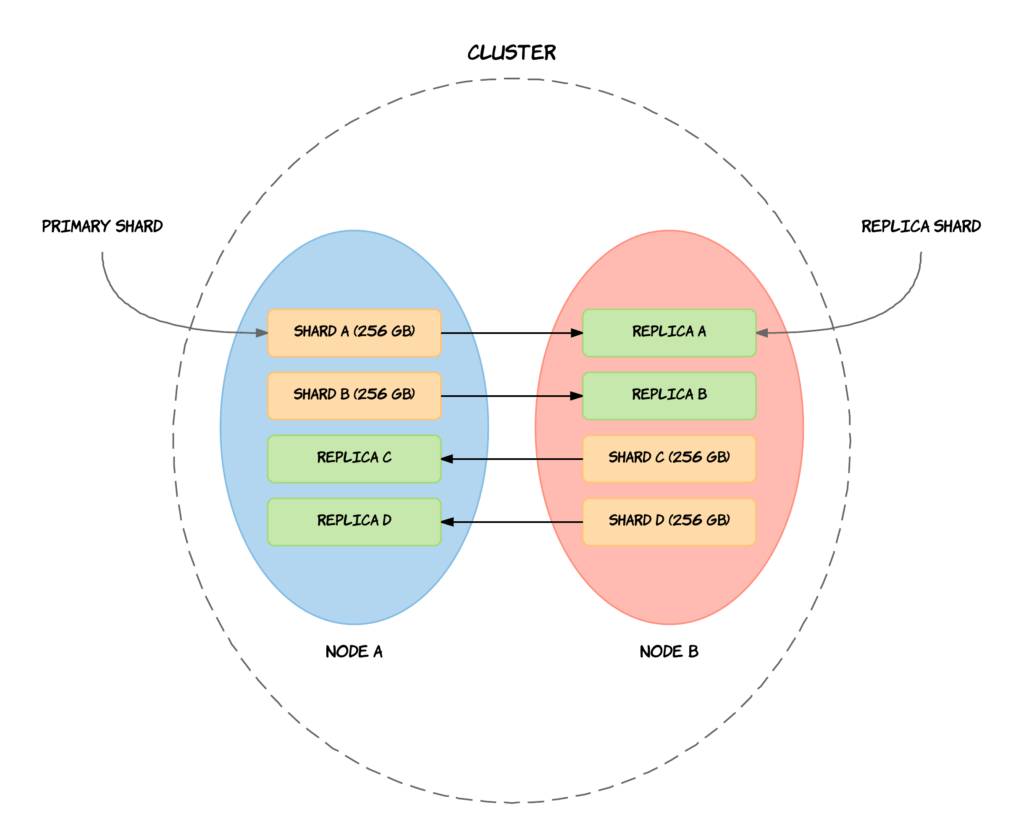
Replication 2 amaca hizmet eder:
Shardlarda olduğu gibi, bir index oluştururken replica sayısı belirtilir ve bu varsayılan olarak 1 dir. Varsayılan replica her shard için 1 tanedir.

Cluster içerisindeki primary shard index oluşturma işlemleri için giriş görevi görür. Document ekleme, güncelleme veya kaldırma gibi indexi etkileyen tüm işlemler primary sharda gönderilir. Primary shard bu işlemleri doğrulamaktan sorumludur. İşlem primary shard tarafından kabul edildikten sonra, cluster daki replica shard lara iletilecektir. Birden fazla replica varsa paralel bir şekilde iletilecektir. İşlem her replica shardda başarılı bir şekilde tamamlandığı ve primary sharda yanıt verildiğinde, primary shard cliente başarıyla tamamlandığına dair yanıt verir. Aşağıdaki şemada bu döngü görselleştirilmiştir.