
Dokuz Eylül Üniversitesi, Üretim Yönetimi ve Endüstri İşletmeciliği alanında Tezsiz Yüksek Lisans yapan Ramazan YEL arkadaşımızın bu konuda hazırladığı sunumu indirmek için tıklayınız . Kendisine teşekkür ediyoruz bilgisini paylaştığı için.
Giriş
Makine öğrenimi yapay zekanın bir alt alanıdır (AI). Makine öğreniminin amacı genel olarak verilerin yapısını anlamak ve bu veriyi insanlar tarafından anlaşılabilir ve kullanılabilir modellere uydurmaktır.
Makine öğrenimi bilgisayar bilimleri alanında bir alan olmasına rağmen, geleneksel hesaplama yaklaşımlarından farklıdır. Geleneksel hesaplamada, algoritmalar hesaplamak veya problem çözmek için bilgisayarlar tarafından açıkça programlanmış talimatlar setidir. Makine öğrenme algoritmaları bunun yerine bilgisayarların veri girdileri üzerinde eğitim almalarını ve belli aralıktaki değerleri çıkartmak için istatistiksel analizi kullanmalarını sağlar. Bu nedenle makine öğrenimi, bilgisayarların veri girdilerine dayalı karar verme süreçlerini otomatik hale getirmek için örnek verilerden model kurmalarını kolaylaştırır.
Günümüzdeki herhangi bir teknoloji kullanıcısı, makine öğreniminden faydalanmıştır. Yüz tanıma teknolojisi, sosyal medya platformlarının kullanıcıların arkadaşlarının fotoğraflarını etiketlemesine ve paylaşmasına yardımcı olmasını sağlar. Optik karakter tanıma (OCR) teknolojisi, metin görüntülerini hareketli bir türe dönüştürür. Makine öğrenimi ile desteklenen öneri motorları, kullanıcıların tercihlerine göre film veya televizyon programlarının nelerin izleyeceğini önermektedir. Makineyi gezmeyi öğrenmeye dayanan kendiliğinden sürüş arabaları yakında tüketicilere sunulabilir.
Makine öğrenimi sürekli gelişen bir alandır. Bu nedenle, makine öğrenme metodolojileri ile çalışırken göz önünde bulundurmanız gereken bazı hususlar veya makine öğrenme süreçlerinin etkisini analiz etmek gerekir.
Bu yazıda, denetimli ve denetlenmeyen öğrenmenin ortak makine öğrenme yöntemlerine ve k-en yakın komşu algoritması, karar ağacı öğrenmesi ve derin öğrenme de dahil olmak üzere makine öğrenmede yaygın algoritmik yaklaşımlara bakacağız. Makine öğrenmesinde hangi programlama dillerinin en çok kullanıldığını keşfedeceğiz, size her birinin olumlu ve olumsuz özelliklerinden bazılarını sunacağız. Ayrıca, makine öğrenme algoritmaları tarafından kalıcı önyargıları tartışacağız ve algoritmalar oluştururken bu önyargıları önlemek için akılda tutulması gereken şeyleri düşünelim.
Makine Öğrenme Yöntemleri
Makine öğrenmede görevler genellikle geniş kategorilere ayrılır. Bu kategoriler, öğrenmenin nasıl alındığına veya geliştirilen sisteme öğrenmeyle ilgili geri beslemenin nasıl verildiğine dayanır.
En çok kabul gören makine öğrenme yöntemlerinden ikisi, insanlar tarafından etiketlenmiş örnek girdi ve çıktı verisine dayanan algoritmaları eğiten gözetim altında öğrenme ve algoritmayı, girdisi içinde yapıyı bulmasına izin vermek için algoritmayı etiketlenmiş veri içermeyen denetlenmeyen öğrenmedir veri. Bu yöntemleri daha ayrıntılı olarak keşfedelim.
Denetimli Öğrenme
Denetlenen öğrenmede, bilgisayar istenen çıktılarla etiketlenmiş örnek girdileri ile donatılmıştır. Bu yöntemin amacı, algoritmanın, hataları bulmak için gerçek çıktısını “öğretilen” çıktılarla karşılaştırarak “öğrenmesini” sağlamak ve buna göre modeli değiştirmek için yapabilmesidir. Denetimli öğrenme, bu nedenle, ek etiketsiz veriler üzerindeki etiket değerlerini tahmin etmek için desenler kullanır.
Örneğin, denetlenen öğrenme ile bir algoritma, balık olarak etiketlenen köpek balıklarının görüntüleri ve su olarak etiketlenen okyanusların görüntüleri ile veri besleyebilir. Bu veriyle eğitilerek denetlenen öğrenme algoritması, daha sonra etiketsiz köpekbalığı görüntülerini balık olarak, etiketlenmemiş okyanus görüntülerini su olarak tanımlayabilmelidir.
Denetimli öğrenmenin yaygın olarak kullanıldığı durum, istatistiksel olarak gelecekteki olası olayları öngörmek için geçmiş verileri kullanmaktır. Gelecekteki dalgalanmaları öngörmek için tarihi borsa bilgilerini kullanabilir veya spam e-postaları filtrelemek için istihdam edilebilir. Denetimli öğrenmede, köpeklerin etiketlenmiş fotoğrafları, köpeklerin etiketlenmemiş fotoğraflarını sınıflandırmak için girdi verileri olarak kullanılabilir.
Denetimsiz Öğrenme
Denetlenmeyen öğrenmede, veriler etiketsizdir, bu nedenle öğrenme algoritması, girdi verileri arasında ortak noktalar bulmak için bırakılmıştır. Etiketsiz veriler etiketli verilere göre daha bol olduğundan, denetimsiz öğrenmeyi kolaylaştıran makine öğrenme yöntemleri özellikle değerlidir.
Denetlenmeyen öğrenmenin amacı, bir veri kümesindeki gizli kalıpları keşfetme kadar basit olabilir, ancak aynı zamanda, hesaplama makinesinin ham verileri sınıflandırmak için gerekli temsilleri otomatik olarak keşfetmesine olanak tanıyan bir özellik öğrenme hedefine de sahip olabilir.
Denetimsiz öğrenme, işlem verisi için yaygın olarak kullanılır. Geniş bir müşteri kitlesine ve satın alımlarına sahip olabilirsiniz, ancak bir insan olarak, benzer özelliklerin müşteri profillerinden ve satın alma türlerinden ne tür olabileceğini mantıklı bulamayacaksınız. Bu veriler denetimsiz bir öğrenme algoritması ile beslendiğinde, kokusuz sabunlar satın alan belli yaş aralığındaki kadınların hamile kalma ihtimalinin yüksek olduğu ve dolayısıyla hamilelik ve bebek ürünleriyle ilgili bir pazarlama kampanyasının bu kitleye sırayla hedef olabileceği belirlenebilir Satın alma sayısını artırmak için.
“Doğru” bir cevap söylenmeden, denetlenmeyen öğrenme yöntemleri görünebilir.
Uzaya yeni bir nesne eklendiğinde – bu durumda yeşili bir kalp – makine öğrenme algoritmasının kalbi belirli bir sınıfa sınıflandırmasını isteyeceğiz.

K = 3’ü seçtiğimizde, algoritma, elmas sınıfına ya da yıldız sınıfına sınıflandırmak için yeşil kalpteki en yakın üç komşuyu bulacaktır.
Diyagramımızda, yeşil kalpteki en yakın üç komşu bir elmas ve iki yıldız. Bu nedenle, algoritma kalbi yıldız sınıfıyla sınıflandırır.
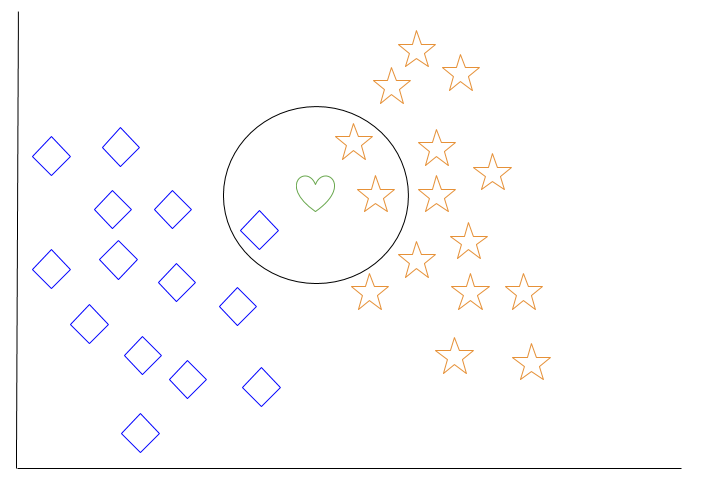
Makine öğrenme algoritmalarının en temelleri arasında, k-yakın komşu, sisteme sorgu yapılıncaya kadar eğitim verilerinin ötesinde genelleme yapılmadığı için “tembel öğrenme” türü olarak kabul edilir.
Karar Ağacı Öğrenme
Genel kullanım için, karar ağaçları, görsel olarak kararları temsil etmek ve karar vermeyi göstermek veya bildirmek için kullanılır. Makine öğrenme ve veri madenciliği ile çalışırken, karar ağaçları bir tahmin modeli olarak kullanılır. Bu modeller, verilere ilişkin gözlemleri, verilerin hedef değeri ile ilgili sonuçlara göre eşleştirir.
Karar ağacı öğrenmesinin amacı, girdi değişkenlerine dayanan bir hedefin değerini tahmin edecek bir model oluşturmaktır.
Tahmini modelde, gözlem yoluyla belirlenen verilerin özellikleri dallarla temsil edilirken, verilerin hedef değeri ile ilgili sonuçlar yapraklarda gösterilir.
Bir ağacı “öğrenirken” kaynak veri, türetilmiş alt kümelerin her birinde tekrar tekrar bulunan bir öznitelik değeri testine dayalı alt kümelere bölünür. Bir düğüm alt kümesi, hedef değeri olduğu gibi eşdeğer bir değere sahip olduğunda, yineleme işlemi tamamlanmış olur.
Birisinin balık tutup tutmayacağını belirleyebilen çeşitli koşullara bir örnek verelim. Bu, hava koşullarını ve barometrik basınç koşullarını içerir.
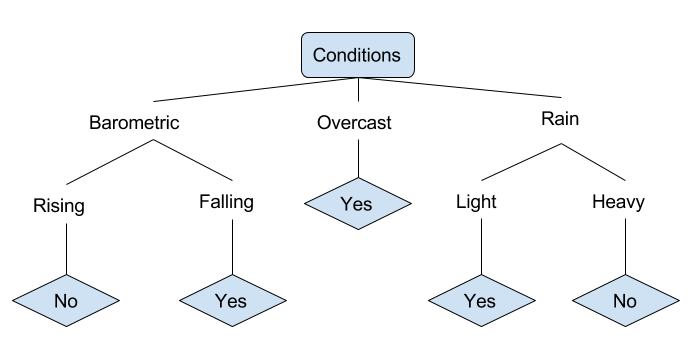
Yukarıdaki basitleştirilmiş karar ağacında, bir örnek ağaca göre uygun yaprak düğümüne göre sınıflandırılarak sınıflandırılır. Bu daha sonra belirli bir yaprak ile ilişkili sınıflandırmayı döndürür, bu durumda bu bir Evet veya Hayır’dır. Ağaç, balıkçılık yapmak için uygun olup olmadığına dayalı bir günün koşullarını sınıflandırır.
Gerçek bir sınıflandırma ağacı veri setinin, yukarıda özetlenenin çok daha fazla özelliği olurdu, ancak ilişkiler belirlemek için açık olmalıdır. Karar ağacı öğrenme ile çalışırken, hangi özellikleri seçeceğiniz, bölmek için hangi koşulları kullanacağınız ve karar ağacının ne zaman net bir sonuca ulaştığını anlamak gibi çeşitli belirlemeler yapılmasına ihtiyaç vardır.
Derin Öğrenme
Derin öğrenme, insan beyninin hafif ve sesi uyarıları görme ve işitme sürecine nasıl taklit edebileceğini taklit eder. Derin bir öğrenme mimarisi, biyolojik sinir ağlarından esinlenmiştir ve donanım ve GPU’lardan oluşan bir yapay sinir ağında birden fazla katmandan oluşur.
Derin öğrenme, verilerin özelliklerini (veya temsillerini) ayıklamak veya dönüştürmek için doğrusal olmayan işlem birimi katmanları kaskatını kullanır. Bir katmanın çıktısı ardışık katmanın girişi olarak işlev görür. Derin öğrenmede, algoritmalar ya gözetim altında tutulabilir ve verileri sınıflandırmak ya da denetimsiz olarak görev yapabilir ve model analizi yapabilir.
Şu anda kullanılan ve geliştirilen makine öğrenme algoritmaları arasında derinlemesine öğrenme en çok bilgiyi absorbe eder ve bazı bilişsel görevlerde insanlara yenebilir. Bu özniteliklerden dolayı, derin öğrenme, yapay zeka alanında önemli bir potansiyel olan yaklaşım haline geldi
Bilgisayar görme ve konuşma tanıma hem derin öğrenme yaklaşımlarından önemli ilerlemeler gerçekleştirmiştir. IBM Watson, derin öğrenmeyi sağlayan bir sistemin iyi bilinen bir örneğidir.
Programlama dilleri
Makine öğrenimi konusunda uzmanlaşacak bir dil seçerken, mevcut iş ilanlarında listelenen becerilerin yanı sıra makine öğrenme süreçleri için kullanılabilen çeşitli dillerde mevcut kitaplıkları düşünebilirsiniz.
Aralık 2016’da indeed.com’da iş ilanlarından alınan verilere göre, Python’un makine öğrenme alanında en çok aranan programlama dili olduğu söylenebilir. Python’ı Java, ardından R, daha sonra C ++ izliyor.
Python’un popülaritesi, TensorFlow, PyTorch ve Keras gibi son zamanlarda bu dil için mevcut derin öğrenme çerçevelerinin artan gelişimine bağlı olabilir. Okunabilir sözdizimi ve bir komut dosyası dili olarak kullanılabilme özelliği olan bir dil olan Python, verileri önceden işleme ve doğrudan veri ile çalışma için güçlü ve açıktır. Scikit öğrenen makine öğrenme kütüphanesi, Python geliştiricilerinin zaten tanıdık ettiği mevcut birkaç Python paketinin üzerine, yani NumPy, SciPy ve Matplotlib üzerine kurulmuştur.
Python’u kullanmaya başlamak için, “Nasıl Yapılır Python 3’te” konusundaki eğitsel serimizi okuyabilir veya “Python’da bir Makine Öğrenme Sınıflandırıcısı nasıl scikit ile öğrenilir” veya “Nasıl Yapılır Sinir Stili Aktarımı ile Nasıl Yapılır” konusunu okuyabilirsiniz. Python 3 ve PyTorch. ”
Java kurumsal programlamada yaygın olarak kullanılır ve genellikle kurumsal düzeyde makine öğrenimi üzerinde çalışan ön uç masaüstü uygulama geliştiricileri tarafından kullanılır. Genellikle makine öğrenimi hakkında bilgi edinmek isteyen programcıların ilk tercihi olmaz ancak makine öğrenimine uygulamak için Java gelişiminde geçmişe sahip olanlar tarafından tercih edilir. Sektördeki makine öğrenme uygulamaları açısından, Java, siber saldırı ve sahtekarlık bulma kullanım örnekleri de dahil olmak üzere, ağ güvenliği için Python’dan çok daha fazla kullanılmaya eğilimli.
Java için makine öğrenme kütüphaneleri arasında Java ve Scala için yazılmış açık kaynaklı ve dağıtılmış derin öğrenme kütüphanesi Deeplearning4j vardır; MALLET (LanguagE Toolkit için Ana Öğrenme), doğal dil işleme, konu modelleme, belge sınıflandırma ve kümeleme dahil olmak üzere metin üzerinde makine öğrenme uygulamaları sağlar; ve Weka, veri madenciliği görevleri için kullanılacak bir makine öğrenme algoritmaları koleksiyonu.
R, öncelikle istatistiksel hesaplama için kullanılan açık kaynak programlama dilidir. Son yıllarda popülaritesi arttı ve akademik çevrede pek çok kişi tarafından tercih edilmektedir. R genellikle endüstri üretim ortamlarında kullanılmaz, ancak veri bilimi alanındaki artan ilgi nedeniyle endüstriyel uygulamalarda artmıştır. R’de makine öğrenimi için kullanılan popüler paketler, tahmini modeller oluşturmak için caret (sınıflandırma ve regresyon eğitimi için kısadır), sınıflandırma ve regresyon için randomForest ve istatistik ve olasılık teorisi için fonksiyonları içeren e1071’i içerir.
C ++, oyun veya robot uygulamalarında (robot lokomosyonu dahil) makine öğrenimi ve yapay zeka için tercih edilen dildir. Gömülü bilgi işlem donanımı geliştiricileri ve elektronik mühendisleri, makina öğrenme uygulamalarında, C ++ veya C’yi, dil yeterlilikleri ve kontrol seviyeleri nedeniyle daha çok tercih eder. C ++ ile kullanabileceğiniz bazı makine öğrenme kitaplıkları, ölçeklenebilir mlpack, geniş kapsamlı makine öğrenme algoritmaları sunan Dlib ve modüler ve açık kaynaklı Shark’ı içerir.
İnsan Önyargıları
Veriler ve hesaplamalı analiz bize objektif bilgi aldığımızı düşünmemize neden olabilir, ancak durum böyle değildir; verilere dayalı olması, makine öğrenme çıktılarının tarafsız olması anlamına gelmez. İnsan önyargılarının, verilerin nasıl toplandığı, organize edildiği ve nihai olarak, makine öğrenmesinin bu verilerle nasıl etkileşim kuracağını belirleyen algoritmalarda rol oynar.
Örneğin, insanlar “balık” için bir algoritma eğitmek için veri olarak görüntüler sunuyorsa ve bu insanlar ezici çoğunlukla altınböcek görüntülerini seçerse, bir bilgisayar bir köpek balıkını balık olarak sınıflandıramaz. Bu, köpek balıklarına karşı balık gibi bir önyargı yaratacak ve köpekbalığı balık sayılamayacaktı.
Bilim adamlarının tarihsel fotoğraflarını eğitim verisi olarak kullanırken, bilgisayar da aynı zamanda renkli ya da kadın olan bilim insanları sınıflandıramayabilir. Aslında, son zamanlarda yapılan hakemli bir araştırma, AI ve makine öğrenme programlarının, ırk ve cinsiyete dayalı önyargıları içeren insan benzeri önyargılar sergilediğini ortaya koymuştur. Bakınız, örneğin “Dil kurumlarından otomatik olarak türetilen semantik, insan benzeri önyargılar içeriyor” ve “Erkekler Alışverişi sever: Cinsiyet Önemini Azaltma, Kodlama Düzeyinde Kısıtlamalar kullanarak İndirme” [PDF].
Makine öğrenimi iş dünyasında giderek artan bir şekilde etkilenirken, yakalanmayan önyargılar, insanların kredilere hak kazanmasını, yüksek ödeme imkânı bulan iş fırsatları için reklam göstermesini veya aynı gün teslimat seçeneklerini almasını engelleyebilecek sistemik sorunları kalıcı hale getirebilir.
İnsan önyargısı başkalarını olumsuz etkileyebileceğinden, bunun farkında olmak ve mümkün olduğunca ortadan kaldırmak için çalışmak son derece önemlidir. Bunu başarmak için çalışmanın bir yolu, bir projede çalışan çeşitli insanların olmasını ve çeşitli insanların bunu test etmesini ve gözden geçirmesini sağlamaktır. Diğerleri, düzenleyici üçüncü partileri, algoritmaları izlemek ve denetlemek, önyargıları tespit edebilecek alternatif sistemler oluşturmak ve veri incelemesi proje planlamasının bir parçası olarak ahlak araştırmaları yapmaları çağrısında bulunmuşlardır. Önyargılar hakkında farkındalığın artırılması, kendi bilinçsiz önyargılarına dikkat etmek ve makine öğrenme projelerindeki ve boru hatlarındaki eşitliği yapılandırmak, bu alanda önyargılarla mücadele etmek için çalışabilir.

Sonuç
Bu eğitimde, makine öğrenmesinin, alanlarda kullanılan yaygın yöntemlerin ve popüler yaklaşımların, uygun makina öğrenme programlama dillerinin kullanım durumlarının bazıları gözden geçirildi ve algoritmalarda bilinçsiz önyargılar çoğaltılırken akılda tutulması gereken bazı şeyler de ele alındı.
Makine öğrenimi, sürekli yenilenmekte olan bir alan olduğundan algoritmaların, yöntemlerin ve yaklaşımların değişmeye devam edeceğini akılda tutmak önemlidir.
“Scikit-öğrenme ile Python’da bir Makine Öğrenme Sınıflandırıcısı Nasıl Oluşturulur” veya “Python 3 ve PyTorch ile Sinirsel Stil Aktarımı Nasıl Gerçekleştirilir?” Konusundaki öğreticilerimizi okumanın yanı sıra, teknoloji endüstrisinde veri ile çalışmayla ilgili daha fazla bilgi alabilirsiniz. Veri Analizi öğreticilerimizi okurken.